Модели данных в СУБД
Иерархическая модель данных
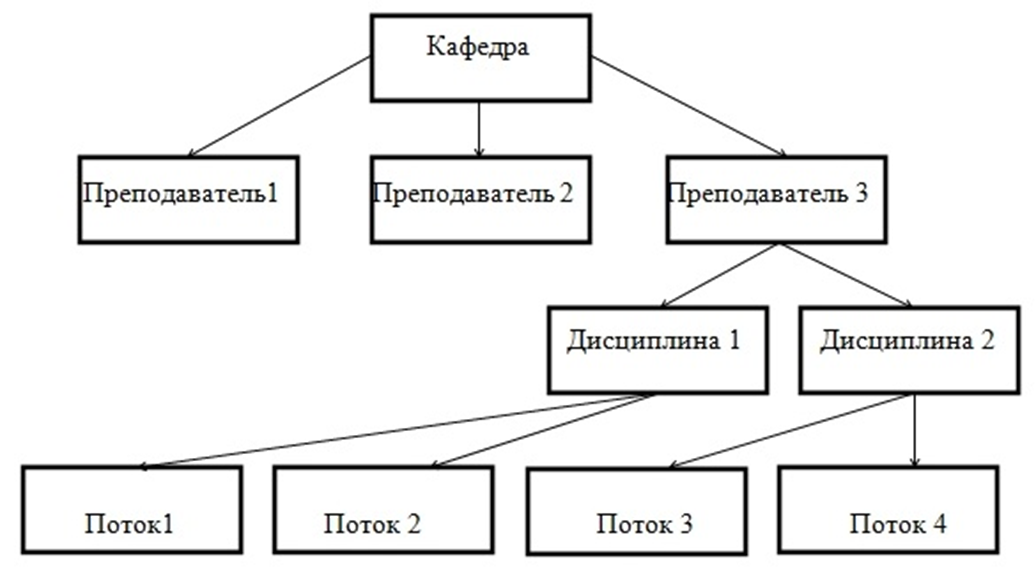
Иерархическая модель данных — это модель данных, где используется представление базы данных в виде древовидной (иерархической) структуры, состоящей из объектов (данных) различных уровней. Между объектами существуют связи, каждый объект может включать в себя несколько объектов более низкого уровня. Такие объекты находятся в отношении предка (объект более близкий к корню) к потомку (объект более низкого уровня), при этом возможна ситуация, когда объект-предок имеет несколько потомков, тогда как у объекта-потомка обязателен только один предок.
Основные достоинства иерархической модели данных:
- эффективное использование памяти ЭВМ;
- высокая скорость выполнения основных операций над данными;
- удобство работы с иерархически упорядоченной информацией;
- простота при работе с небольшим объемом данных так как, иерархический принцип соподчиненности понятий является естественным для многих задач.
Недостатки иерархической модели данных:
- громоздкость такой модели для обработки информации с достаточно сложными логическими связями;
- трудность в понимании ее функционирования обычным пользователем;
- трудность в применении к данным со сложной внутренней взаимосвязью;
- исключительно навигационный принцип доступа к данным.
Сетевая модель данных
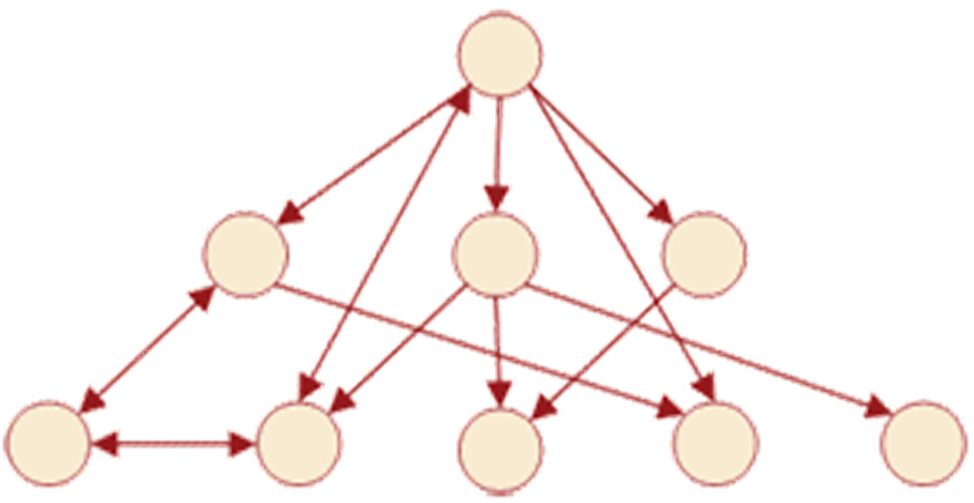
Сетевая модель представляет собой структуру, у которой любой элемент может быть связан с любым другим элементом. Сетевая база данных состоит из наборов записей, которые связаны между собой так, что записи могут содержать явные ссылки на другие наборы записей, тем самым наборы записей образуют сеть. Связи между записями могут быть произвольными, и эти связи явно присутствуют и хранятся в базе данных. Сетевая модель данных может быть представлена математической структурой, которая называется направленным графом.
Достоинства сетевой модели данных:
- минимальная избыточность;
- возможность эффективной реализации по показателям затрат памяти и оперативности;
- предоставляет больше возможностей (по сравнению с иерархической моделью) в смысле допустимости образования произвольных связей.
Недостатки сетевой модели данных
- высокая сложность и жесткость схемы БД, построенной на ее основе;
- сложность в понимании и обработки информации в БД обычному пользователю;
- сложно осуществлять операции поиска.
Реляционная модель данных
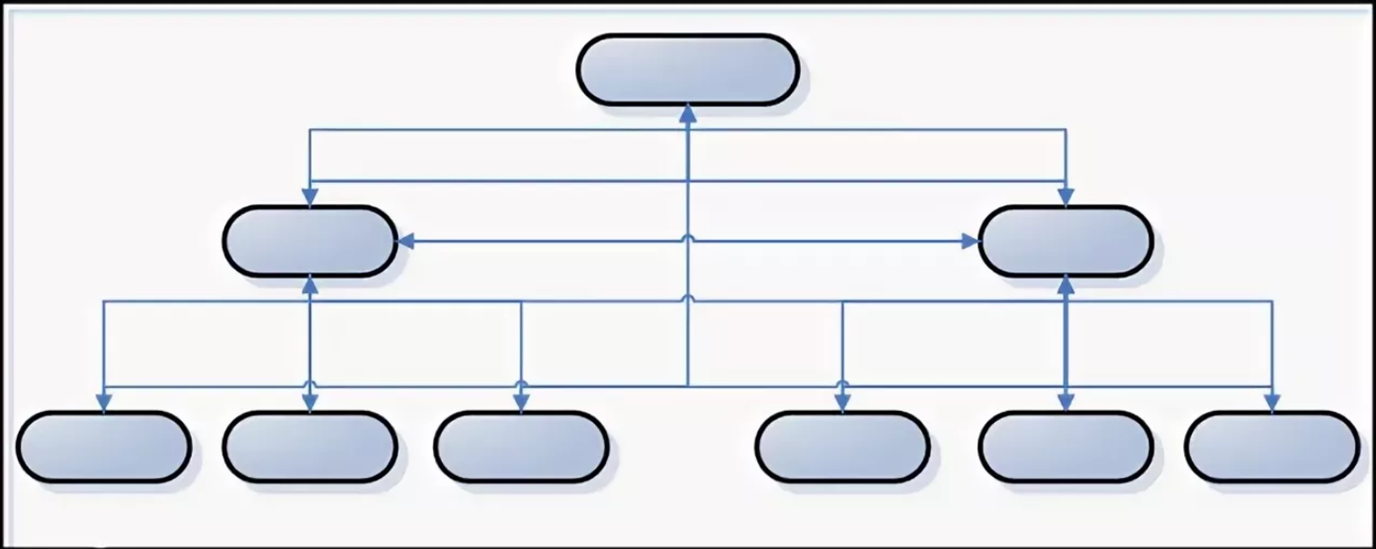
Реляционная модель - совокупность данных, состоящая из набора двумерных таблиц. В теории множеств таблице соответствует термин отношение (relation), физическим представлением которого является таблица. В сравнении с иерархической и сетевой моделью данных, реляционная модель отличается более высоким уровнем абстракции данных.
Достоинства реляционной модели данных:
- изложение информации в простой и понятной для пользователя форме (таблица)
- реляционная модель данных основана на строгом математическом аппарате, что позволяет лаконично описывать необходимые операции над данными
- независимость данных от изменения в прикладной программе при изменении
- позволяет создавать языки манипулирования данными не процедурного типа
- для работы с моделью данных нет необходимости полностью знать организацию БД
Недостатки реляционной модели данных
- относительно медленный доступ к данным
- трудность в создании БД основанной на реляционной модели
- трудность в переводе в таблицу сложных отношений
- требуется относительно большой объем памяти
Системы управления базами данных класса NoSQL
- база данных ключ-значение
- распределённое хранилище (Column-oriented)
- документо-ориентированные СУБД
- БД на основе графов
База данных ключ-значение
База данных «ключ-значение» (англ. key-value database или англ. key–value store) — парадигма хранения данных, предназначенная для хранения, извлечения и управления ассоциативными массивами (они же словари или хеш-таблицы). Словари содержат коллекцию объектов или записей, которые, в свою очередь, содержат множество различных полей, каждое из которых содержит данные. Эти записи хранятся и извлекаются с использованием ключа, который однозначно идентифицирует запись и используется для быстрого поиска данных в базе данных. Как ключи, так и значения могут представлять собой что угодно: от простых до сложных составных объектов.
Особенностями БД типа ключ-значение являются:
- отсутствие схем;
- изменяющаяся структура данных;
- отсутствие целостности/согласованности;
- легкое масштабирование (репликация Master-Slave);
- высочайшая производительность и доступность;
- отсутствие сложных запросов;
- возможность транзакций.
Часто встречающиеся случаи применения БД хранилищ ключ-значение:
- Кеширование - быстрое и частое сохранение данных для будущего использования
- Очередь - некоторые БД типа ключ-значение поддерживают списки, наборы и очереди
- Распределение информации/задач - используется для реализации паттерна Pub/Sub
- Живое обновление информации - приложения использующие состояния
Некоторые популярные хранилища:
- Redis - БД в оперативной памяти с дополнительной отказоустойчивостью
- Riak - Распределенное, репликационное хранилище
- Memcached / MemcacheDB - распределённая БД в оперативной памяти
Колоночно-ориентированные базы данных
Колоночно-ориентированная база данных – это не что иное, как двумерный массив, где каждый ключ (строка) содержит одну или несколько пар ключ-значение, привязанных к нему. Такая система позволяет хранить и использовать большие объемы неструктурированных данных (одна строка с большим количеством дополнительной информации). Если реляционные БД — это строко-ориентированные, «горизонтальные» БД, то колоночно-ориентированные — это БД, ориентированные на столбцы, «вертикальные».
Особенностями колоночно -ориентированных БД являются:
- применимость для разреженных данных;
- использование для данных различной структуры;
- встроенная распределенность (шардинг);
- быстрая запись;
- достаточно медленная обработка сложных запросов
Колоночно-ориентированные СУБД применяются, как правило, в аналитических системах класса business intelligence (ROLAP) и аналитических хранилищах данных (data warehouses).
Примером этого решения служат:
- Cassandra — хранилище, основанное на BigTable и DynamoDB;
- HBase — хранилище для Apache Hadoop, основанное на принципах BigTable.
Документо-ориентированные базы данных
Документо-ориентированная БД (англ. document-oriented database) – разновидность нереляционных БД, специально предназначенная для хранения иерархических структур данных (документов). В основе документо-ориентированных СУБД лежат документные хранилища (англ. document store), имеющие структуру дерева. Структура дерева начинается с корневого узла и может содержать несколько внутренних и листовых узлов. Листовые узлы содержат данные, которые при добавлении документа заносятся в индексы, что позволяет даже при достаточно сложной структуре находить место (путь) искомых данных. В отличие от хранилищ типа ключ-значение, выборка по запросу к документному хранилищу может содержать части большого количества документов без полной загрузки этих документов в оперативную память.
Преимущества ДОБД:
- имеют лучшую производительность при индексировании больших объемов данных и большом количестве запросов на чтение по сравнению с реляционными базами данных;
- легче масштабируются по сравнению с SQL-хранилищами;
- децентрализуются;
- поддерживают динамическую схему данных, не нужно выполнять никаких операций обновления при добавлении новых полей;
- поддерживают хранение неструктурированных данных;
- имеют единое место хранения всей информации об объекте, меньше операций вида JOIN;
- предоставляют простой интерфейс общения с БД (ключ —> значение, не SQL);
- имеют все достоинства РаБД ключ-значение, поскольку РаБД ключ-значение являются частным случаем документо-ориентированных БД.
Неудобства в использовании ДОБД:
- отсутствие транзакционной логики и контроля целостности. В большинстве информационных систем необходимо реализовывать ее в логике приложения;
- использование дополнительного языка программирования для обработки данных;
- доступ к данным по одному ключу. Несмотря на довольно большой функционал и способность доступа к данным по одному ключу, такой тип имеет ряд своих проблем. Например, при доступе к одному документу он полностью выводится в ответ на запрос, даже если необходимо какое-то одно поле, что сказывается на производительности.
Часто встречающиеся СУБД:
- Couchbase - основанное на JSON, совместимое c Memcached хранилище
- CouchDB - передовое документо-ориентированное хранилище
- MongoDB - очень популярное и функциональное хранилище
Базы данных на основы графов
Базы данных на основы графов - разновидность баз данных с реализацией сетевой модели в виде графа и его обобщений.
Наилучшим применением для БД на основе графов является:
- работа со сложно связанной информацией — хранение связей между двумя сущностями и целого ряда разноуровневых связей между сущностями, не связанных с первыми напрямую;
- моделирование данных и классификация информации по связям.
Примерами графовых СУБД служат:
- OrientDB — очень быстрый документо-ориентированный гибрид типа граф, написанный на Java;
- Neo4j — бессхемное, очень мощное и популярное графовое решение, написанное на Java.